
There is good news and bad news about the evidence for mHealth interventions in low- and middle-income countries. The good news is there that is a lot of evidence from high-quality (counterfactual-based) studies about the effectiveness of mHealth interventions, that is, “a lot” compared to the overall evidence base for low- and middle-income countries. The bad news is that this body of evidence is not very useful for understanding the potential effectiveness of mHealth interventions at scale and over time. In this post, I present some analysis of the evidence base for mHealth interventions, and I argue that going forward, we need to rigorously evaluate the net impact of mHealth interventions in real program settings, at scale, over time and combined with cost-effectiveness analysis.
There is a lot of evidence
One of the 11 categories in the ICT4D evidence map is mHealth, which we define as interventions that use mobile and wireless devices to provide medical care. Of the 253 impact evaluations captured in the map, 147 are studies of mHealth interventions – by far the most evaluated intervention category in the map. So that’s the good news! Even compared to the evidence for other topics and sectors catalogued in other evidence maps for low- and middle-income countries, the quantity of studies for mHealth is large.
Most evidence comes from pilots
The evidence comes from small samples
For the subset of mHealth studies, I along with my fabulous then-intern Katherine Whitton coded each study for the sample size used for estimating the net effect of the intervention. All but three of the included studies measure outcomes at the individual level. The average sample size across the studies is 761, but this average is driven by a huge outlier. The median sample size is only 328. The scatterplot in figure 1 below shows the distribution of sample sizes with a single outlier above 20,000. Many of these samples are also convenience or purposive samples. For example, the researchers recruit participants from patients attending a clinic over a certain period of time. Typically, the researchers then randomly assign the recruited patients to treatment and control, so the internal validity of the findings is strong, but the sampling method and size weaken the external validity of the findings.
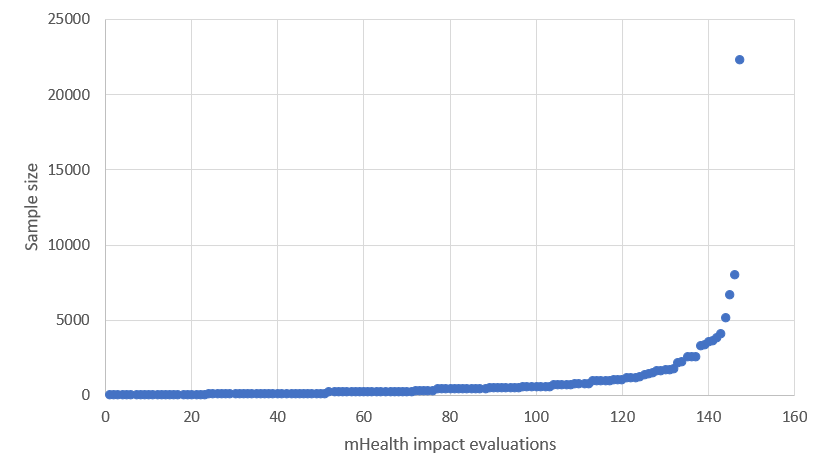
Figure 1. Scatterplot of study sample sizes
The duration of implementation is short
Katherine the great and I also coded the mHealth studies for the length of time the intervention was implemented before the end-line outcome data were collected. From the ICT4D evidence map data, we also know whether or not there were any outcomes measured after end-line. The average duration of implementation of the mHealth interventions studied is 27 weeks, or roughly six months. Similar to the sample size variable, however, this average is driven by outliers. The median duration is only 17 weeks. And only 12 of the 147 studies measure the outcome any time after the initial end-line.
It may certainly be the case that these interventions are designed to have effects after a short period of time, so the short durations may be appropriate to test the mechanism of the intervention. It is difficult to believe, however, that the first 17 weeks of any program is reflective of the program over time. In other words, these short durations also do not have ecological validity. One of the issues I raise in my pilot-to-scale post is the novelty effect. Cool new tools and approaches may have large effects in the beginning but then lose effect over time, as anyone who has learned to turn notifications off can attest. The novelty effect is one reason why it is so important to evaluate interventions over the long run.
Few studies measure cost
Discussion
From the standpoint of measuring attributable effect sizes, we have a lot of high-quality evidence about the effectiveness of mHealth interventions. Unfortunately, this evidence is not very useful for programming. It comes from evaluations of pilot interventions, implemented on small samples, over short periods of time without measuring outcomes at any point after the initial end-line. And these evaluations do not provide cost data to help evidence users assess cost-effectiveness. Some may argue that these impact evaluations test mechanisms, and the programs at scale can then be evaluated with monitoring data or non-counterfactual implementation science. I caution against that, especially where we have novel interventions in contexts that are complex and rapidly changing.
Let’s look at an example. Nsagha et al. (2016) test an SMS reminder intervention for improving adherence to treatment and care among people living with HIV and AIDS in Cameroon. Forty-five treatment patients received four messages a week for four weeks while the 45 control patients received standard of care. After the four weeks, 64.4% of the treatment group adhered to antiretroviral medications and only 44.2% of the control group did (p = 0.05). This result is promising, but it is measured on a sample size of 90 after only four weeks. And the simple intervention is addressing a complex problem.
The authors document for the sample that the reasons for missing treatment and for non-adherence are, in descending order of prevalence, late homecoming, involvement in outdoor business, antiretroviral stockout, forgetfulness, traveling out of station without medication, and not belonging to a support group. The SMS reminders can help with forgetfulness and perhaps traveling out of station without medication, but not with the others. Put differently, there are many factors that influence adherence, and SMS reminders do not address them all.
Suppose this pilot intervention is scaled up and monitored over the course of a year. Would you feel comfortable attributing a before-and-after change in adherence of 10 percentage points entirely to the SMS reminders? It does matter how much of that change you attribute to the intervention, because that is the only way to know whether the money you are spending on the SMS system is worthwhile. What if adherence decreased by 10 percentage points? Would you conclude that the SMS reminders had a negative effect on adherence?
My point is simply that small pilots can be very useful for establishing feasibility and identifying promising mechanisms, but to inform programmatic decisions about mHealth, we need more evidence from rigorous evaluations conducted on programs at scale and over time.
This post is based on a lightning talk I delivered at the 2018 Global Digital Health Forum in Washington, DC. The supplementary materials for this research are available here.
Photo credit: Ericsson/CC BY-NC-ND 2.0 license


