
There are many debates about the definitions and distinctions for replication research, particularly for internal replication research, which is conducted using the original dataset from an article or study. The debaters are concerned about what kinds of replication exercises are appropriate and about how (and whether) to make determinations of “success” and “failure” for a replication. What everyone seems to agree, however, is that the most basic test – the lowest bar for any publication to achieve – is that a third party can take the authors’ software code and data and apply the code to the data to reproduce the findings in the published article. This kind of verification should be a no-brainer, right? But it turns out, as reported in a newly published article in PLOS ONE, only 25% of the articles Benjamin D.K. Wood, Rui Müller, and I tested met this bar. Only 25% are verifiable!
I suspect (hope) that this finding raises a lot of questions in your mind, so let me try to answer them.
Why did you test this?
In our quest to use replication terms that are self-explanatory (see here for other examples) we decided to call it push button replication – you can push a button to replicate the findings presented in the tables and figures in a published study. As children of the Midwest United States, we also thought the PBR acronym was fun.
How did you test this?
We started by selecting a sample of articles to test. Our work at 3ie revolved around development impact evaluations, so we focused on these types of studies. One advantage of studying research within this set is that the studies use similar quantitative methods, but span many sectors and academic disciplines. We used the records in 3ie’s Impact Evaluation Repository for the period 2010 to 2012 to identify the top ten journals publishing development impact evaluations. Then we screened all the articles published in those ten journals in 2014 for those that qualified as development impact evaluations. We ended up with a sample of 109 articles.
That was the easy part. We also developed a detailed protocol for conducting a push button replication. The protocol outlines very clear procedures for requesting data and code, pushing the button, and selecting a classification. We piloted and then revised the protocol a few times before finalizing it for the project. We also created a project in the Open Science Framework (OSF) and posted the protocol and other project documents there for transparency.
With the sample and the protocol in hand, we set out to attempt push button replications for each article. At this point Rui joined the team and offered to take on all the economics impact evaluations in the sample as part of his master’s thesis.
What did you find?
We present the primary results in figure 1 in the paper, which is copied below. For the majority of the articles in the sample (59 out of 109) the authors refused to provide the data and code for verification. They just said no. Even some who stated in their articles that replication data would be provided upon request just said no when we made that request. And even some who published in journals requiring that replication files be provided just said no. Not just some, a lot. The authors of ten of 20 articles from the Journal of Development Economics and 24 of 34 articles from PLOS ONE, both journals with requirements for providing replication files, refused to provide data and code for verification.
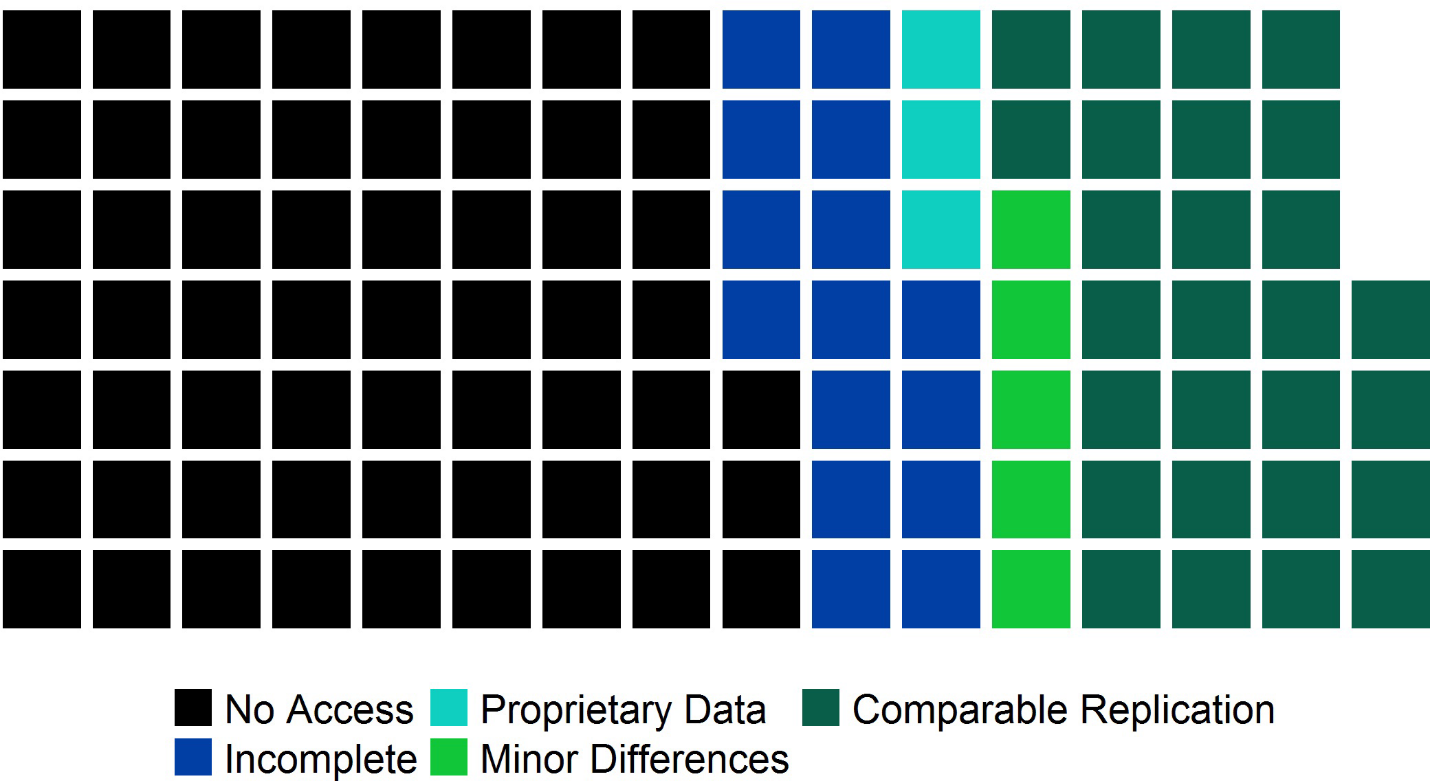
Figure 1. Push button replication classification results for entire sample
But, you say, some of those data must be proprietary! Yes, some of the authors claimed that, but they needed to prove it to be classified as proprietary data. We rejected six unsubstantiated claims but did classify the three substantiated claims as having propriety data (the turquoise squares).
You might be saying to yourself, “why would authors give access to their code and data if they didn’t know what you were going to do with them?” But they did. The push button replication protocol and the description of our project were publicly available, and we offered to sign whatever kind of confidentiality agreement regarding the data was necessary. You might also be objecting that we didn’t give them enough chances or enough time. But we far exceeded our stated protocol in terms of the number of reminders we sent and the length of time we waited. In fact, we would have accepted any replication files that came in before we finalized the results, so authors really had from our first request in 2016 until we finalized the results early in 2018 to provide the data.
We did receive data for 47 articles. For 15 of these, we received data and code but not enough to fully reproduce the tables and figures in the published articles. These are classified as incomplete (the royal blue squares). For the rest, the news is good. Of the 32 articles that we were able to push button replicate, 27 had comparable findings. Five had some minor differences, especially when focusing on the tables tied to the articles’ key results.
Do these findings matter?
You might look at the figure and conclude, “only five complete push button replications found minor differences”, so that’s good news! Well, yes, but I see this this way: for twenty of the 47 articles for which we received data, we know that the authors’ data and code cannot completely or comparably reproduce the published findings. That’s 43%. Is there any reason to believe that the rate is lower for those articles for which the authors refused to provide the files? I don’t think so. If anything, one might hypothesize the opposite.
Our conclusion is that much of the evidence that we want to use for international development, evidence from both the health sciences and the social sciences, is not third-party verifiable. In the PLOS ONE article, we present additional results, including the classifications by each of the ten journals and the results according to some of the funders of these studies.
What do you recommend?
First, unfortunately, it is not enough for a journal to simply have a policy. Many academics do not respect policies that the journals do not enforce. The exception to this in our sample was American Economic Journal: Applied Economics. It had an upon-request policy, and we received the data and code for six out of eight articles, with the other two meeting the requirements to be classified as proprietary data.
Second, many health scientists and social scientists are lagging not just in research transparency practices, but also in good research practices. Even for publications as recent as 2014, many authors did not maintain complete data and code to reproduce their published findings. Fifteen of 47 for which we received files did not have complete files to send. In many fields there are formal and informal associations of researchers who are pushing for better practices, but I believe that sea change will require firm action on the part of journals.


