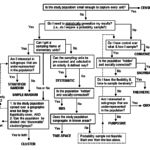
In part I, I reviewed how the principles of probability samples apply to household sampling for valid (inferential) statistical analysis and focused on the challenges faced in selecting enumeration areas (EAs). When we want a probability sample of households, multi-stage sampling approaches are usually used, where EAs are selected in the first stage of sampling and households then selected from the sampled EAs in the second stage. (Additional stages may be added if deemed necessary.) In this post, I move on to the selection of households within the sampled EAs. I’ll focus on the sampling principles, challenges, approaches and recommendations.
Once EAs are selected, a random sample of households must be selected from all eligible households in the EA. Even if the number of households in the EAs is provided by the census bureau, it’s always important to update it before selection. Remember, you need to know the correct number of households from which the sample will be selected, so you can track selection probabilities.
Let me tell you about the (in)famous “spin the bottle” approach. It goes something like this: the field team lands on the selected enumeration area; they find the center of the area; then they spin a bottle, start walking in the pointed direction and screen houses as they go. They select eligible households using a systematic process (e.g., select one in every five eligible households). If the first household to interview is selected randomly, this is still considered a random sample (with some limitations). So, what’s wrong with spinning the bottle, you may ask?
First, the process usually stops when the targeted sample size is achieved. If you don’t go through the entire area screening every household for eligibility, this process would miss portions of the population within the selected area, usually those in the outskirt of the neighborhoods. Second, this process is hard to monitor and document. How do you know the field team didn’t spin the bottle several times until the direction that is easiest to access is “selected”? How do you know that the first household in the selected direction was randomly selected? Will you know how many households were eligible for selection? Does spinning the bottle avert the validity threat? Maybe or maybe not 🙁 .
In our East Africa study discussed in part I, my colleagues and I did the following to reduce threats to validity in the household sampling. We printed household listing forms for each of the selected EAs with all EA identifying information pre-filled; we provided instructions for listing households; we gave a random number for each EA; and we wrote out instructions for identifying the random start and the systematic process for selecting households. These forms were reviewed in the field by the field supervisors and were also entered into an electronic database for further quality checks and record keeping.
Preserving the integrity of the selection of households and data collection, as discussed so far, will give you the probability sample your heart desired. However, let’s not lose sight of the many challenges that can arise unexpectedly in any given survey. For example, in our East Africa study, the local project lead and overall field work manager quit in the middle of data collection; some interviewers resigned and additional staff had to be quickly trained to replace them; and we had issues securing the necessary equipment for anthropometric measurements. Although probably not immediately obvious, these problems can also lead to deviations from the sampling principles, and can threaten the validity of the data collected. Always prepare for the unexpected. Preparation will save you lot of perspiration.
How rigorous a probability sample is will be judged on how well you stick to the sampling principles. Nothing is 100% foolproof though; all you can do is minimize the chances for deviating from the sampling principles, document the processes, and account for the implementation problems in the analysis and interpretation of the findings. Happy sampling!
I’d like to acknowledge Eskindir Tenaw and Patrick Olsen for their contributions to the sampling processes in our East Africa study highlighted in this blog post.