Sampling is the process of selecting a subset of things (your sample) from a larger group of things (your study population) for inclusion into a study. “Things” can be individuals, groups, chunks of time, events, places, documents or any other type of unit that might interest an inquiring mind.
How we sample directly influences both the degree of generalizability (or not), and the validity (or not), of a study’s findings. Sampling is also one of the most common study design elements ornery scientific reviewers scour, looking for weaknesses to attack.
To help folks build stronger sampling plans for their research and evaluation projects, we present a series of three sampling posts.
This first post explains basic sampling terminology and describes the most common sampling approaches with emoji-themed graphics (let’s face it – who wants to actually READ about sampling). Sampling approaches featured in the image gallery above include:
- Simple random sample
- Systematic sample
- Stratified random sample
- Time-space sample
- Cluster sampling: stage 1
- Cluster sampling: stage 2
- Convenience sampling
- Theoretical inductive sampling
- Snowball sampling
- Respondent-driven sampling
- Purposive sample, example 1
- Purposive sample, example 2
- Quota sample
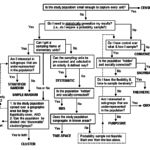
In the sequel blog, we provide eager readers with a sampling decision tree (refer to the previous parenthetical statement about reading aversion), to give them some guidance on when to choose one sampling method versus another.
In our third post, we offer empirically-derived recommendations for choosing sample sizes for qualitative inquiry (sorry… this one requires some reading).
Sit down, hold on to your hats and glasses, and enjoy the sampling ride!
Download the full slide deck.
All imagery used in the sampling series slides are in the public domain under Creative Commons CCO, retrieved from Pixabay. All slides are published here solely for educational purposes.